Yapay zeka çalışmaları başlangıçta beyin benzeri değil, sembolik mantık sistemlerine dayalı şekilde geliştirilmiştir. 1956 yılında düzenlenen Dartmouth Konferansı, yapay zekâ kavramını ilk kez tanımlayan ve bu alanda öncü isimleri bir araya getiren kritik bir dönüm noktasıydı. John McCarthy, Marvin Minsky, Claude Shannon ve Allen Newell gibi öncüler, o tarihlerde makinelerin mantıksal sembollerin oluşturduğu örgüler ile yapay bir zeka yürütebileceğini savundular.
Bu yaklaşım, sinir sistemini modellemekten çok, matematiksel çıkarım sistemlerini temel alıyordu. Günümüzde hayatımıza yön veren GPT, DALL·E, Stable Diffusion gibi derin öğrenme tabanlı sistemlerin teorik temelleri ise 1980’li yıllarda Geoffrey Hinton, Yoshua Bengio ve Yann LeCun tarafından atıldı. Ancak o yıllarda donanım kısıtlamaları nedeniyle bu çalışmalar yeterince ilgi görmedi ve sadece akademik çalışmalarla sınırlı kaldı.

Yapay zekânın gelişimi yalnızca metin ve görsel üretimiyle sınırlı kalmadı. AlphaGo, Dota 2, StarCraft II gibi karmaşık dijital oyunlar, yapay zekâ modellerinin çevre koşulları altında karar alma yeteneklerini test etmek için birer deney ortamına dönüştü. Bu ortamlar, belirsizlik, zaman baskısı ve stratejik planlama gibi parametreleri içerdiği için yapay zekâ sistemlerinin pratikte ne kadar yetkin olduğunu gözlemlemeyi mümkün kıldı.
Bugün geldiğimiz noktada GPT-3 gibi modeller yaklaşık 175 milyar parametre içerirken, insan beyninde bunun yaklaşık 100 katı olan 100 trilyon sinaps bulunduğu tahmin edilmektedir. Bu karşılaştırma bire bir denk olmasa da, yapay zekâ sistemlerinin henüz biyolojik zekânın karmaşıklığına ulaşmadığını gösterir. Bu, yapay zekânın hâlen biyolojik zekâya göre çok daha “küçük” olduğu anlamına gelse de, ortaya koyduğu sonuçlar toplumu etkileyecek düzeydedir. Bu da yapay zekâ modellerinin henüz tam anlamıyla potansiyelinin ortaya çıkmadığını, ancak buna rağmen insan benzeri üretim ve karar verme kabiliyeti sergileyebildiğini gösterir.
Yapay zekâ, insan benzeri bilişsel işlevleri taklit edebilen; öğrenen, çıkarım yapan ve karar verebilen algoritmik sistemler bütünüdür. Bu sistemler; öğrenme, akıl yürütme, problem çözme, anlama ve hatta yaratıcı düşünme gibi zihinsel becerileri taklit edebilir. Büyük veri ile ilgili yazım için ziyaret edebilirsiniz: https://emrecicek.net/big-data-ve-makine-ogrenmesi/
Yapay zeka, çok büyük miktarda veriyi analiz ederek ve bu verilerden örüntüler çıkararak öğrenmektedir. Aslında temel çalışma mantığı istatistiksel hesaplamaları yapmaktır ama sonuçları etkileyici boyuttadır. Bu aşamada öğrenmek sadece yorumlamak ile sınırlı kalmamakta, aynı zamanda belirli olayları taklit edebilmektedir. Yapay zekanın sahip olması gereken 3 temel faktör bulunmaktadır.
Veri: Yapay zekanın öğrenmesi için ihtiyaç duyduğu “ham madde”.
Algoritmalar: Veriyi analiz eden ve örüntüleri bulmaya çalışan matematiksel yapılar.
Hesaplama Gücü: Bu işlemleri gerçekleştirmek için gerekli teknolojik altyapı.
Bu durumda günümüzde kullanılan yapay zekayı ayıran nokta, üretkenlik noktasında sadece sahip olduğu verilerin ışığında, yorum yapabilir ya da taklit edebilir olmasıdır. Yapay Zeka sistemleri genellikle makine öğrenmesi yöntemi ile eğitilmekte ve sistemin kendisine verilen ya da topladığı verilerden örüntüleri çıkararak öğrenmesini sağlamaktadır.
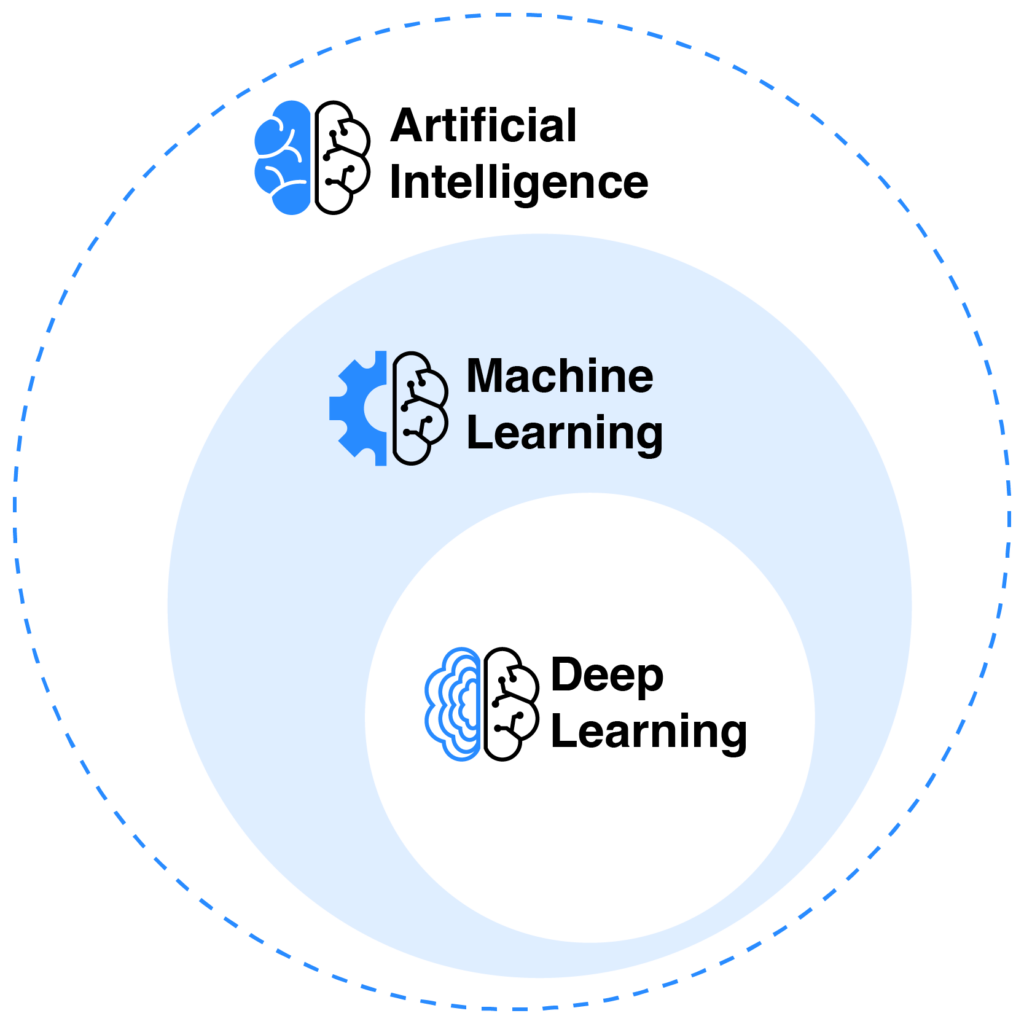
Yapay Zeka çalışma alanlarına bağlı olarak 3 gruba ayrılmaktadır. Bugün kullandığımız sistemlerin tamamı dar yapay zekâ kategorisindedir.
- Dar & Zayıf Yapay Zeka Modelleri
Günümüzde kullanılmakta olan ve hayatımızı kolaylaştırdığına inandığımız bir çok yapay zeka modeli bu gruba dahil olmaktadır. Otomatik çeviri özelliğine sahip uygulamalar, Siri, Alexa, Google Asistan benzeri uygulamalar, Youtube, Spotify, Netflix gibi içerisindeki öneri sistemlerini belirli bir hizmet için sunan uygulamalar, ChatGPT, DeepSeek, Copilot, Gemini, Midjourney, Soundraw, Suno gibi kaynaklardan topladığı verileri harmanlayarak doğrudan sunan uygulamaları kapsamaktadır.
- Geniş & Güçlü Yapay Zeka Modelleri
İnsan zekâsına eşdeğer, her konuda öğrenebilen ve düşünebilen yapay zeka modellerini kapsamaktadır. Günümüzde teorik düzeyde ve üzerine çalışılmaya devam edilmekte olan sistemlerdir.
- Süper Yapay Zeka Modelleri
İnsan zekasını aşması beklenilen, farkındalığın, duygunun, algının ve karar alma yetisine sahip olması beklenilen ve günümüzde henüz örneklerini göremediğimiz modelleri kapsamaktadır.
Karmaşık süreçler, kusurlu veya bilinmeyen durumları dikkatle inceleyebilmek için bazı özel araçları kullanmak gerekmektedir. Yapay zeka araçlarını kullanarak makineleri belirli konularda bilgilendirmek ve birden fazla sonucu, olasılığı, hata payını sahip olduğu bilgiler doğrultusunda projekte etmek süreçleri kolaylaştırmaktadır. Hata olasılığını minimuma indirmek ve zaman kazanmak için kullanışlı görünmektedir.
Yapay Zeka Çalışma Mantığı
Yapay zekâ modelleri doğal dili “kelimeler” ya da “cümleler” olarak değil, onları oluşturan küçük parçalara yani token adı verilen hecelere benzer yapılara bölerek işler. Bu işlemi yapan sisteme tokenizer denir. Örneğin, “Emre Çiçek Mühendistir” ifadesi model için şöyle görünebilir:
["Em", "re", " ", "Çi", "çek", " ", "mü", "hen", "dis", "tir"]
Tokenizer doğru çalışmazsa model tüm bağlamı hatalı anlar. İki farklı tokenizer ile aynı modelden çok farklı çıktılar almak mümkündür. Byte Pair Encoding (BPE) ve Unigram gibi teknikler, günümüz dil modellerinde sıkça kullanılan tokenizasyon algoritmalarıdır. Özellikle OpenAI, tokenizer mimarisini optimize ederek hem modeli hızlandırmış hem de yanıt doğruluğunu artırmıştır. Yani yapay zeka sistemlerinin, kendilerine verilen komutları anlaması bu parçalama sistemine bağlıdır.
Modern yapay zekâ modellerinin temelinde “Transformer” mimarisi yer alır. 2017 yılında tanıtılan bu yapı, dikkat mekanizmasını kullanarak her kelimenin ya da kavramın bağlamını anlayabilen çok katmanlı bir modelleme sistemidir. LLM (Büyük Dil Modeli) olarak bilinen sistemler bu yapı üzerine kurularak milyarlarca parametre ile öğrenme gerçekleştirir. Transformer, geleneksel ardışık yapılardan farklı olarak tüm girdileri aynı anda işler ve bağlamı çok daha doğru analiz edebilir.
Yapay Zekânın Yeni Mimarisi
Yapay zekâ sistemleri artık sadece modellerden ibaret değil; kendi kararlarını alabilen, çevresiyle etkileşim kurabilen, araçlar kullanan ve sürekli öğrenen ajanlar olmaya başladı. Yapay zekâ sistemlerinin yüzeyde görünen kısmı, yani kullanıcıların doğrudan etkileşime geçtiği model çıktısı, aslında sistemin sadece son ürünüdür. Bu çıktının kaliteli, anlamlı ve göreve uygun olabilmesi, modelin ardında çalışan çok sayıda görünmeyen ama kritik altyapı ve karar mekanizmalarına bağlıdır. Bu gelişimi anlayabilmek için “Agentic AI Layer 8 Architect” olarak bilinen sekiz katmanlı mimariden söz etmek gerek.
Çalışma prensibini ve mimari yapıyı anlamak, kuruluşların bu sistemleri etkili bir şekilde uygulamasına yardımcı olur. Agentic AI’nın 8 katmanlı mimarisi, otonom ajanların karmaşık ortamlarda bağımsız olarak algılamasını, akıl yürütmesini, öğrenmesini ve hareket etmesini sağlayan gelişmiş bir çerçeveyi temsil eder. Bu kapsamlı yapı, güvenilirlik, güvenlik ve etik uyumluluğu korurken minimum insan müdahalesiyle çalışabilen AI sistemleri oluşturmak için gerekli bileşenleri sağlar.

1. Infrastructure (Altyapı Katmanı)
Altyapı Katmanı, herhangi bir aracı AI sisteminin doğru çalışabilmesi için gereken donanım ve bulut sistemlerini içerir. Temel bilgi işlem kaynaklarını ve bağlantı yöntemlerini kapsar. Bu temel katman, sağlam sistem performansını garanti eden birkaç kritik bileşenden oluşur. Güçlü ve ölçeklenebilir bir altyapı olmadan yapay zekâ ajanları verimli çalışamaz. Ajanların optimize maliyetle büyük veri ve modelleri işlemesi için bellek, CPU/GPU gücü ve düşük gecikme süreli ağ erişimi gerekir.
Yoğun makine öğrenimi hesaplamaları için GPU’lar, genel işlem görevleri için CPU’lar ve belirli AI iş yükleri için özel donanımlar dahil olmak üzere birincil işlem omurgası olarak temeli oluşturur. Dağıtılmış sistem bileşenleri arasında kesintisiz iletişimin sağlanmasında önemli rol oynar. Yüksek hızlı ağ yetenekleri, farklı katmanlar ve harici sistemler arasında hızlı veri alışverişini mümkün kılarken, sağlam bağlantı protokolleri, çoklu ajan ortamlarında güvenilir ajan-ajan iletişimini garanti eder.
Depolama Sistemleri hem kalıcı veri depolama hem de yüksek hızlı bellek erişimi sağlar. Bu sistemler, yapılandırılmış veri tabanlarından yapılandırılmamış multimedya içeriklerine kadar çeşitli veri türlerini işlemeli ve otonom işlemler için veri bütünlüğünü ve kullanılabilirliğini sağlamalıdır.
2. Agent Internet (Ajan İnterneti Katmanı)
Ajan İnternet Katmanı, bir yapay zekâ ajanının dış dünya ile bağlantı kurmasını sağlayan dijital etkileşim katmanıdır. Bu katman, bir ajanın görevleri yerine getirebilmesi için ihtiyaç duyduğu çevrimiçi kaynaklara, veri servislerine ve diğer ajanlarla olan iletişim ortamlarına erişimini sağlar. Modern yapay zekâ uygulamaları için bilgiye ulaşmak kadar bu bilgiyi yapılandırmak ve gerçek zamanlı kullanmak da kritik önem taşır.
Katmanın temel bileşenleri arasında web tarayıcı arabirimleri, API istemcileri, veri akışı sağlayan abonelik mekanizmaları (örneğin RSS, webhook) ve servis bazlı bağlantı protokolleri yer alır. Ajan, bu katman sayesinde arama motorları üzerinden bilgi çekebilir, SaaS sistemleriyle entegre olabilir veya diğer yazılımlarla (örneğin CRM, ERP, e-posta sunucuları) doğrudan veri alışverişi gerçekleştirebilir.
Gerçek zamanlı veri ihtiyaçları olan bir ajan için Agent Internet katmanı, haber akışlarına erişim, canlı finans verileri, kullanıcı hareketleri, konum servisleri gibi dinamik veri kaynaklarını yakalayan bir sinir ağı gibi davranır. Dış bağlantılar sayesinde ajanın Katman 5 süreci doğrudan bilgiyle beslenir ve karar verme kapasitesi artar.
Ayrıca bu katman, çoklu ajan sistemlerinde eşzamanlı çalışmayı mümkün kılar. Farklı ajanlar birbirine bağlanabilir, görevleri başka ajanlara devredebilir veya farklı sistemler ya da yapay zeka ürünleri ile birlikte çözüm üretebilir. Bu bağlamda Agent Internet katmanı, yalnızca dış veri erişimi değil, aynı zamanda bir “ajan ekosistemi” içerisinde ortak çalışabilirliğin altyapısını sunar.
Güvenlik ve erişim yönetimi açısından bu katman, oturum yönetimi, veri kimlik doğrulama (authentication) ve veri şifreleme gibi güvenlik mekanizmalarını da desteklemelidir. Aksi takdirde, ajanın maruz kaldığı dış veri akışı manipülasyona açık hale gelebilir ve ortaya çıkabilecek olan zafiyetlerin değerlendirilmesi durumunda kişisel veriler ya da gizli bilgiler için risk söz konusudur.
Ajan tabanlı çalışan yapay zeka sistemleri yalnız çalışmak zorunda değildir. Birden fazla ajanın birlikte çalıştığı senaryolarda görev paylaşımı, senkron mesajlaşma ve hata durumlarında görevi devretme gibi stratejiler kullanılır. Bu ajanlar, mesaj dizilerini paylaşarak durumu değerlendirir ve belirlenen hedefe daha verimli biçimde ulaşır. Birden fazla ajanın eş zamanlı çalıştığı ortamlarda, bu iletişimi standart hale getiren protokoller ve paylaşılan hafıza alanları kullanılır.
3. Protocol (Protokol Katmanı)
Protokol Katmanı, ajan tabanlı yapay zekâ sistemlerinde dış sistemlerle güvenli, tutarlı ve yapılandırılmış veri alışverişini mümkün kılan iletişim kuralları ve veri formatları kümesini temsil eder. Bu katman, ajanın internete veya diğer servis sağlayıcılarına erişmesini teknik düzeyde düzenlerken, sistemlerin bir arada ve doğru şekilde çalışabilirliğini sağlar.
Modern yapay zekâ uygulamaları, farklı kaynaklardan gelen veri akışlarını işleyebilmek için çok sayıda farklı protokolle çalışmak zorundadır. Bu bağlamda Protocol katmanı, HTTP(S), WebSocket, gRPC, GraphQL, MQTT, RESTful API, SOAP gibi iletişim protokollerini destekleyerek ajanların hem senkron hem de asenkron veri kaynaklarıyla etkileşime girmesini sağlar. Veri formatları düzeyinde ise bu katmanda JSON, XML, YAML, CSV ve Protobuf gibi standartlar devreye girer.
Ajanlar, bu formatları doğru şekilde serileştirme (serialization) ve ayrıştırma (parsing) işlemleri ile kullanarak dış sistemlerden aldıkları verileri anlamlı ve kullanılabilir hale getirir. Örneğin, bir ajanın REST API üzerinden gelen JSON yanıtı işlemesi ya da GraphQL üzerinden gelen sorguları yorumlayarak içerik üretmesi bu katmanın temel görevidir.
Kimlik doğrulama ve yetkilendirme mekanizmaları da protokol katmanının kritik bileşenlerindendir. JSON Web Token, API key tabanlı güvenlik politikaları gibi yöntemlerle, ajanların belirli servislere kimlikli ve kısıtlı erişim sağlaması kontrol altına alınır. Özellikle çoklu kullanıcı ortamlarında, farklı ajanların farklı erişim politikalarına sahip olması gerekir ve bu da protokol düzeyinde çözülmelidir.
Ayrıca bu katman, veri bütünlüğü ve aktarım güvenliği açısından TLS/SSL şifrelemesi, HMAC doğrulama, nonce kullanımı ve yeniden iletim veya yönlendirme bazlı saldırı önleyici stratejileri de kapsamalıdır. Aksi takdirde, ajanların komutları değiştirilerek kötü niyetli eylemler tetiklenebilir veya hassas veri sızdırılabilir.
Protokol katmanı, sadece ajan ile dış dünya arasındaki etkileşimi değil, aynı zamanda ajanlar arası protokol adaptasyonunu da içerir. Örneğin bir ajan WebSocket ile çalışan bir mikroservise veri gönderirken, diğer ajan HTTP tabanlı bir arayüzden bilgi alıyor olabilir. Bu tür heterojen haberleşme senaryolarında protokol dönüştürücüler aracılığıyla arayüz eşlemesi yapılarak doğru çıktıların sunulması sağlanır.
Sonuç olarak Protocol katmanı, ajan tabanlı mimarinin iletişim sinir sistemidir. Doğru yapılandırılmamış bir protokol altyapısı, veri kayıplarına, güvenlik açıklarına ve sistemler arası uyumsuzluğa neden olabilir. Bu nedenle bu katmanın hem mühendislik hem de siber güvenlik açısından özenle tasarlanması gerekir.
4. Tooling Enrichment (Araç Zenginleştirme Katmanı)
Araç Zenginleştirme Katmanı, bir yapay zekâ sisteminin yalnızca bilgi üretmekle sınırlı kalmayıp, gerçek görevleri yerine getirebilen işlevsel bir yapıya dönüşmesini sağlayan bileşendir. Bu katman, sistemin harici dijital araçları kullanarak karmaşık işlemleri gerçekleştirmesini, hedef odaklı eylemler üretmesini ve çevresiyle daha aktif bir şekilde etkileşim kurmasını mümkün kılar.
Çeşitli yazılım sistemleri, web servisleri ya da bilgi işleme modülleri ile entegre çalışarak, dış sistemlerden veri alabilmeyi, işleyebilmeyi, dönüştürebilmeyi veya dışa aktarabilmeyi sağlar. Böylece yalnızca metin tabanlı yanıtlar üretmekle kalmayıp görevleri uygulayabilen bir sisteme dönüşürler. Aynı zamanda, ajanın hangi aracı ne zaman ve nasıl kullanacağını belirleyen mantıksal karar yapılarının ve stratejik kullanım akışlarının da dahil olduğu bir süreçtir. Böylece ajanın hangi senaryoda hangi aracın uygun olacağına dair kararlar modellenir.
Her bir araç için kullanılabilirlik, işlevsel kapasite, veri türü uyumu gibi teknik ayrıntılar önceden tanımlanır. Yapay zeka sistemi, bu bilgiler doğrultusunda hangi aracın kullanılacağını seçebilir ve görev akışını buna göre şekillendirebilir. Araçlardan alınan çıktıların değerlendirilmesi ve görev başarı durumuna göre yeni eylem planlarının oluşturulması da yine bu katmanda yürütülür. Ajan, bir aracı kullandıktan sonra elde ettiği sonucu analiz ederek hedefe ulaşma sürecinde bir sonraki adımı planlayabilir.
Bu yapı, yapay zekâ sistemine yalnızca bilgi üretme değil, aynı zamanda karar alma ve uygulama becerisi kazandırır. Böylelikle sistem, kullanıcının talebini anlayarak yalnızca yanıt üretmekle kalmaz, aynı zamanda bu talebi gerçekleştirmek için gerekli adımları dış araçlar yardımıyla uygulamaya koyar. Bu sayede pasif bir bilgi sistemi değil, aktif bir görev icracısı haline gelir.
Görev paylaşımı, araç seçimi ve veri yönlendirme süreçleri yapay zekânın bilişsel katmanıyla entegre biçimde çalışır. Yapay zeka sistemi, görev hedefi doğrultusunda daha önceki kullanım verilerini göz önünde bulundurarak araç tercihinde bulunabilir. Böylece geçmiş deneyimlerden öğrenme süreci de bu katmana dâhil olur. Harici araçlarla çalışan bir yapı olduğu için, hem sistem içi hem de sistem dışı veri akışlarının yetkilendirilmiş ve denetlenebilir olması gerekir.
Son yıllarda geliştirilen bazı mimari yaklaşımlar, bu katmanın temelini oluşturmaktadır. Özellikle araç kullanımı ile akıl yürütmeyi birleştiren sistemler sayesinde yapay zekâ, daha doğal ve etkili çalışmaktadır. Böylece yalnızca bilgiye dayalı değil, eyleme dönük karar süreçleri de ortaya çıkmış olur.
5. Cognition & Reasoning (Bilişsel ve Akıl Yürütme Katmanı)
Bilişsel ve Akıl Yürütme Katmanı, herhangi bir aracı AI sisteminin çevresinden aldığı bilgileri işleyerek mantıklı, hedef odaklı kararlar vermesini sağlayan zihinsel süreçlerin yürütüldüğü merkezdir. AI sistemlerinin düşünen kısmını temsil eder. Bu katman, durum değerlendirmesi, görev planlaması, bağlamsal analiz ve problem çözme gibi yüksek seviye yetenekleri içerir. Temel bileşenler şunlardır:
- Durum Farkındalığı: Ajanın mevcut bağlamı analiz etmesi sürecidir, görev önceliklerini veya kullanıcının niyetini anlaması ile geçen süreyi kapsar.
- Plan Üretimi: Belirli bir hedefe ulaşmak için çok adımlı ve kapsamlı işlem akışlarının kurgulanma sürecidir.
- Karar Ağacı: Şartlı kurallar, önceden tanımlı politikalar veya öğrenilmiş davranış modelleriyle karar alınması sürecidir.
- Hata Yönetimi: Başarısız görevlerin tespit edilip yeniden planlanması, alternatif yolların devreye alınması sürecidir.
Ajan burada sadece mantıksal çıkarımlar yapmaz; belirsizlik, eksik veri veya çelişkili girdilerle karşılaştığında da davranışlarını dinamik şekilde güncelleyebilir. İstenilen sonuca doğru varmak için geçmiş örüntülerden faydalanabilir ya da plandaki alternatif yollara yeni akışlar kurgulayarak ekleyebilir. Bu katmanın sağlıklı çalışması için Katman 6 ve Katman 4 ile güçlü bir veri alışverişi gereklidir. Bu katman üzerinde kararın neden alındığına dair sonuçlar ortaya koyulurken; diğer katmanlarda alınan kararların nasıl uygulanacağı belirlenir.

Bu bilişsel yapıların işlerlik kazanabilmesi için ajanların yalnızca eğitildikleri verilerle sınırlı kalmamaları gerekir. Gerçek dünyadaki görevlerde, çoğu zaman eğitim sırasında modelin görmediği, dinamik ve değişken bilgilere ihtiyaç duyulur. İşte tam bu noktada, RAG (Retrieval-Augmented Generation) devreye girer. Bu yapı, ajanın mevcut bağlamı daha isabetli değerlendirebilmesi ve karar süreçlerini gerçek zamanlı veriye dayandırabilmesi için büyük önem taşır.
Akıl yürütme sürecinin bir parçası olarak RAG, modelin dış bilgi kaynaklarına (örneğin belgeler, veritabanları, API’ler veya güncel internet içeriği) erişmesini sağlar. Bu sayede ajan, yalnızca ezberlenmiş bilgiyle değil, duruma özgü, güncel ve bağlamsal veriyle desteklenmiş kararlar alabilir. Böylece model ezber dışı düşünme ve akıl yürütme becerisi kazanır, güncel veri ile daha mantıklı ve bağlama uygun sonuçlar üretir.
Not: Yapay zekâ modelleri bazen “hallucination” olarak adlandırılan, gerçekle ilgisi olmayan fakat ikna edici yanıtlar üretebilir. Bu durum, sistemin eğitildiği veriden yanlış sonuçlar çıkarması ya da yeterli bağlam olmadan üretim yapmasından kaynaklanır. RAG (Retrieval-Augmented Generation) sistemleri bu sorunu azaltmak için modelin dış kaynaklardan bilgi çekmesini sağlar. Ancak güvenilir sonuçlar elde etmek için model çıktılarının doğrulanması, gerekirse insan gözetimi ile sınanması gerekir.
6. Memory & Personalization (Hafıza ve Kişiselleştirme Katmanı)
Hafıza ve Kişiselleştirme Katmanı, bir yapay zekâ sisteminin sahip olduğu geçmiş deneyimleri, kullanıcılarla olan etkileşim geçmişi ve bağlamsal bilgileri hatırlayarak daha akıllı, tutarlı ve kişiselleştirilmiş çıktılar üretmesini sağlayan yapıdır. Böylelikle yapay zeka ajanı, istenilen veriler karşısında doğru veya hatalı sunulan çıktılar sonucunda aldığı dönütler ile kendini geliştirmiş olur.
Doğru sonuçlar bir sonraki aşamada oluşturacağı akış diyagramları için olumlu dönüt sağlarken, hatalı sonuçlar bir sonraki aşamada farklı akış diyagramları üzerinden nasıl bir planlama yapılacağına dair öngörü sağlar. Bu durumda Katman 6 içerisinde hem epizodik hafıza (bireysel olaylar ve kullanıcı etkileşimleri) hem de semantik hafıza (genel bilgi ve dünya bilgisi) bileşenlerini içerir. Bu katmanda yer alan hafıza sistemleri aşağıdaki türlerde sınıflandırılabilir:
- Kısa Vadeli Hafıza (Working Memory): Anlık görev bağlamını, geçici değişkenleri ve o oturumdaki karar izlerini tutar.
- Uzun Vadeli Hafıza (Persistent Memory): Ajanın görev geçmişi, kullanıcı tercihleri, önceki başarılar/başarısızlıklar gibi kalıcı bilgiler içerir.
- Retrieval-Augmented Memory (RAM): Bilgiye erişimi hızlandırmak için vektör arama bazlı geri çağırma sistemleri içerir (örneğin FAISS, Pinecone, Weaviate). Vektör araması, büyük bir veri kümesindeki öğeleri hızla bulmak için bilgi alma ve makine öğrenmesinde kullanılan bir tekniktir.
- Kişiselleştirme Profilleri: Kullanıcıya özgü davranış modelleri, dil tercihleri, tonlama ayarları, içerik uzunluğu gibi parametreleri barındırır.
Veri işleme düzeyinde bu katman, embedding temelli sorgu eşleme, vektör benzerliği, hafıza adresleme mekanizmaları ve zaman damgalı kayıt dizileri ile çalışır. Embedding, verileri daha düşük boyutlu, sürekli vektörler şeklinde temsil eden bir matematiksel dönüşüm yöntemidir.
Ayrıca sistemler arası veya sistem-insan etkileşimlerinde “geçmişi hatırlama” yetisi, çok adımlı görevlerde bağlamsal tutarlılığı sağlamak için kritik rol oynar. AI sistemleri, bu katman sayesinde bir kullanıcıya daha önce verdiği cevabı hatırlayabilir, önceki görevlerden öğrenerek optimum yolu seçebilir ya da kullanıcı bazlı tutarlılığı sağlayabilir. Bir içerik üretim servisinin, kullanıcı tarafından önceden beğendiği bir yazım tarzına uygun şekilde metin üretmesi bu duruma örnek verilebilir.
Bu kişiselleştirilmiş hafıza yapılarının etkili şekilde çalışabilmesi, yalnızca verinin saklanmasıyla değil, aynı zamanda sistemin bu veriye göre davranışını esnek biçimde uyarlayabilmesiyle mümkündür. İşte bu noktada, LoRA (Low-Rank Adaptation) gibi teknikler devreye girer. Bu yöntem, büyük dil modellerine tam yeniden eğitim gerektirmeden, sadece belirli alt katmanlarında görev veya kullanıcı bazlı adaptasyon yapma olanağı tanır. Böylece yapay zekâ sistemi, geçmiş etkileşimlere veya kullanıcı tercih profillerine göre davranış biçimini güncelleyebilir.
Örneğin aynı soruya farklı kullanıcılar için farklı tonlama ve içerik stratejileriyle yanıt verebilir. LoRA, hafıza katmanındaki kişiselleştirme çıktılarının model davranışına doğrudan yansıtılmasını sağlayarak bu katmanı yalnızca bilgi saklayan değil, davranış belirleyen aktif bir yapıya dönüştürür.
Güvenlik ve gizlilik bağlamında ise bu katman, özel verilerin şifrelenerek saklanması, kişisel veri erişim izinlerinin kontrolü ve GDPR/KVKK gibi regülasyonlara uygun veri yönetimi politikalarını da kapsamalıdır.
Zaman içinde gelişen ve kullanıcı etkileşimleri ile birlikte öğrenen ve bu sayede kullanıcıyla doğru iletişimi kurabilen bir varlığa dönüştürür. Bu katmanın başarısı, tüm sistemin adaptif zekâ seviyesini doğrudan etkiler.
Kişisel Not: Yapay zeka modellerinin popüler olduğu dönemlerde büyük bir çoğunluğun soru olarak kendisini tanıdığı şekilde resmetmesi ya da anlatmasını istediği durum tam olarak bu katman sayesinde gerçekleşmektedir. Daha önce yapılmış olan sohbet geçmişleri, varsa konum servisleri ya da uygulama takipleri gibi bilgiler daha hızlı sonuca varmak üzere kişiselleştirilmiş profillerde kayıtlı tutulur. Bu durumun bir güvenlik açığı yaratıp yaratmayacağı noktasında takdir sizlere kalmış. 🙂
7. Application (Uygulama Katmanı)
Uygulama Katmanı, yapay zekâ mimarisinin nihai çıktılarının kullanıcıyla buluştuğu, sistemin fonksiyonel kabiliyetlerinin somut ürün veya hizmetler biçiminde sunulduğu arayüz katmanıdır. Bu katman, yapay zekâ sistemlerinin karar alma (Katman 5), araç kullanımı (Katman 4) ve kişiselleştirme (Katman 6) becerilerinin kullanıcı deneyimine dönüşmesini sağlar. Bu katmandaki uygulamalar iki temel düzlemde sınıflandırılabilir:
- Görev Odaklı Uygulamalar: Belirli bir işlevi yerine getiren, örneğin e-posta taslağı oluşturan, yazılım hatalarını analiz eden, müşteri sorularını yanıtlayan veya belge özetleyen sistemlerdir.
- Sürekli Etkileşimli Ajanlar: Kullanıcı hayatına entegre biçimde çalışan, proaktif öneriler sunan veya çok adımlı süreçleri otonom yürüten kişisel yapay asistan sistemleridir.
Application katmanı, herhangi bir AI sisteminin kullanıcıyla etkileşime geçtiği front-end bileşenlerini (web arayüzleri, mobil uygulamalar, sesli arayüzler, mesajlaşma botları) içerdiği gibi, arka planda çalışan background ajanları, cron-job tabanlı tetikleyicileri ve webhook/event-driven görevleri de içerebilir. Bu katman için kritik bazı teknik gereksinimler mevcuttur. Bunlar:
- UI/UX Entegrasyonu: Kullanıcı deneyimini optimize eden, anlamlı geri bildirimler ve etkileşimli yanıtlar sunan dinamik arayüzlerdir. UI (User Interface) ve UX (User Experience), dijital ürünlerin kullanıcı odaklı tasarımında temel iki bileşeni ifade eder. UI, bir kullanıcının sistemle etkileşim kurarken karşılaştığı görsel ve işlevsel arayüz öğelerini kapsar; butonlar, menüler, renk paletleri, tipografi ve ikonografi gibi unsurlar UI tasarımının temelini oluşturur. Bu katman, ürünün estetik açıdan tutarlı, erişilebilir ve kullanıcıya sezgisel gelen bir biçimde sunulmasını hedefler. UX ise, ürünün genel deneyim boyutunu ele alır; kullanıcı davranışlarını, hedeflerini ve etkileşim süreçlerini analiz ederek ürünün işlevselliğini, kullanılabilirliğini ve kullanıcı memnuniyetini artırmaya yönelik çözümler sunar.
Not: Yapay zekâ sistemlerinin doğru çıktılar üretebilmesi, yalnızca modelin kapasitesine değil, kullanıcıdan gelen girdinin (prompt) doğru tasarlanmasına da bağlıdır. Prompt engineering, komutların amaca uygun, açık ve doğru bağlama göre yapılandırılması sürecidir. Few-shot, zero-shot, chain-of-thought ve system prompt gibi teknikler sayesinde aynı modelden çok farklı çıktılar alınabilir. Özellikle görev tabanlı çalışan uygulamalarda bu yapı, modelin davranışını doğrudan etkiler. - Orkestratör: Aynı anda birden fazla görevi yürütebilen yapay zekâ sistemlerinin işleyişini yöneten ve koordine eden bir kontrol mekanizmasıdır. Kullanıcıdan gelen yüksek seviyeli bir istek için aşama aşama yapılacak olan işlemleri ayırır ve uygulanmak için ilgili servislere iletir, elde edilen çıktıları da toplar ve birleştirir. Orkestratör, görev sırasında bağlam bilgisini saklar ve ilgili aşamaların kaydını tutar.
Modern Agent sistemleri tek bir modelin çalışmasından çok daha fazlasını içerir. CrewAI, LangChain, AutoGPT, OpenAgents gibi framework’ler; görevlerin ayrıştırılması, kaynakların senkronize kullanımı ve çoklu adımlı işlemlerin yürütülmesi için özelleşmiş orkestrasyon yapıları sağlar. Bu yapılar, tool kullanımı, bellek yönetimi, karar akışı ve görev paylaşımı gibi bileşenleri bütünleştirerek daha akıllı ve otonom ajanlar oluşturur. - Oturum Sürekliliği: Kullanıcının önceki etkileşimlerini hatırlayarak bağlamı sürdüren oturum farkındalığına sahip yapıların kurulduğu teknik birimdir. Hafıza birimi ile entegre çalışır. İlk işlemden sonuca kadar veya farklı aşamalarda dahi iletişimin kesintisiz devam etmesine olanak tanır. Kullanıcıyı tanır ve geçmiş iletişim üzerinden bağlamı korur.
- Performans ve Güvenilirlik: Performans, sistemin kullanıcı isteklerine ne kadar hızlı, doğru ve verimli yanıt verdiğini gösterir. Güvenilirlik, sistemin her zaman doğru, tutarlı ve hatasız sonuçlar üretmesini sağlar. Çünkü sistemin yanıt süresi, başarım oranı ve hata toleransı bu katmanda kullanıcıya doğrudan yansır. Bu aşamada sistem testleri, log analitiği ve hata raporlama sistemleri (Sentry, DataDog) önemlidir. Bu sayede kullanıcının doğru bilgiye en hızlı ulaşmasında önem arz eder.
Özetle uygulama katmanı, bir yapay zeka sisteminin kullanıcıya nasıl göründüğünü ve nasıl hissettirdiğini belirler. Sistem ne kadar güçlü olursa olsun, zayıf bir uygulama katmanı nedeniyle yetersiz veya işlevsiz olarak algılanabilir. Bu nedenle teknik gücün yanında tasarım, erişilebilirlik, kesintisiz iletişim ve kullanıcı alışkanlıkları da önemlidir.
8. Ops & Governance (Operasyon ve Yönetim Katmanı)
Operasyon ve Yönetim Katmanı, yapay zekâ sistemlerinin sürdürülebilir, güvenli, şeffaf ve etik şekilde çalışmasını sağlayan operasyonel ve yönetim mekanizmalarını kapsar. Sistemlerin yalnızca işlevsel değil, aynı zamanda denetlenebilir, kontrol edilebilir ve toplumsal normlara uygun olması bu katmanın temel amacıdır.
Yapay zeka sistemleri, kullanıcılar için farklı profillerde ve kurallarda kontrol listeleri uygular. Bu profiller, satın alım ile hesap yükselterek veya admin erişimleri gibi birden fazla yetkiyi kapsar. Sistemler üzerinde çalışan kimlik doğrulaması, yetkilendirme ve erişim kontrol listeleri (ACL) ile hangi kullanıcıların hangi kaynaklara ne düzeyde erişebileceğini tanımlar.
Gizli bilgilerin sızmasını önleyen içerik filtreleme, role-based access control (RBAC) ve zero trust security modeli de bu düzlemde yer alır. Sistem üzerindeki tüm faaliyetlerinin ayrıntılı şekilde kaydedilmesi için logging sistemleri bulunur. Sistem davranışları, hata raporları, kaynak kullanımı gibi metrikler analiz edilerek performans, güvenlik ve kullanıcı deneyimi optimize edilir. Sistem uptime bilgisi, kaynak tüketimi, zamanlanmış görev süreçleri, yük dengeleme, felaket kurtarma, veri yedekleme, hata toleransı gibi altyapı yönetim stratejileri de bu katmanda değerlendirilir.
Yapay zekâ sistemleri, yalnızca teknik başarı değil; etik uygunluk, toplumsal sorumluluk ve yasal regülasyonlara uyum açısından da değerlendirilmelidir. Yapay zekâ ajanlarının adil, tarafsız, ayrımcılık yapmayan ve etik davranış ilkelerine uygun şekilde hareket etmesi için belirli politikalar da yine bu katmanda devreye alınır. Ayrıca GDPR, KVKK, HIPAA gibi regülasyonlarla uyumluluk; veri gizliliği, unutulma hakkı, kullanıcı rızası gibi ilkelere saygı gösterilmesini gerektirir.
Özellikle çoklu yapay zeka sisteminin bir arada çalıştığı mimarilerde de görev dağılımı, sorumluluk alanları ve birbirleriyle ilişkileri burada tanımlanır. Ayrıca modelin önyargılı sonuçlar üretmesi, ayrımcılığa neden olması gibi durumlar etik çerçevede değerlendirilmelidir. Bu nedenle sistem tasarımında etik denetim mekanizmaları, açıklanabilirlik ilkeleri ve şeffaflık esas alınmalıdır.
LLM sistemlerinin yalnızca eğitilmesi değil, üretim ortamında sürekli izlenmesi, test edilmesi ve gerektiğinde güncellenmesi gerekir. Bu sürece LLMOps adı verilir. Sürüm yönetimi, log analizi, performans izleme, A/B testi, prompt versiyonlama ve kullanıcı geribildirimi analizi gibi süreçler bu başlık altında yürütülür. Böylece sistemin sürdürülebilirliği, güvenilirliği ve uyarlanabilirliği artırılır.
Sonuç olarak Operasyon ve Yönetim Katmanı, sadece teknik stabilite değil; etik, hukuki ve operasyonel sürdürülebilirlik için de olmazsa olmazdır. Bu katman olmadan güçlü bir yapay zekâ ajanı, kısa sürede güvenlik riski, veri ihlali veya toplumsal uyumsuzluk kaynağı haline gelebilir.
LoRA (Low-Rank Adaptation): Mevcut bir modeli yeniden baştan eğitmeden, daha az parametreyle görev bazlı özelleştirmeye olanak tanıyan verimli ince ayar tekniğidir. Kurumsal veya alan özelinde eğitimlerde kullanılır.
- RAG (Retrieval-Augmented Generation): Modelin eğitim verisi dışında kalan bilgi kaynaklarına erişmesini sağlar. Model, güncel verilere sahip değildir; RAG bu açığı kapatarak dış sistemlerden bilgi çeker ve yanıt üretiminde kullanır. Bu sistemler, LLM’in sabit bilgi sınırlarını esnetir.
- Vektör veritabanı + Embedding sistemleri: Vektör veritabanları ise bu temsil biçimini kullanarak semantik benzerlik araması yapar. Embedding sistemleri, kelime veya kavramları sayısal vektörlere dönüştürür. Böylece LLM, sadece harf ya da kelime eşleşmelerine değil, bağlamsal yakınlığa göre de bilgi sorgulaması yapabilir.
Bu bileşenler, modelin klasik soru-cevap sınırlarını aşıp dinamik, ve görev tabanlı sistemlere dönüşmesini sağlar. Aynı zamanda modelin ölçeklenebilirliğini, güncellenebilirliğini ve modülerliğini mümkün kılar.
Ancak bu büyüleyici gelişimin önemli bir bedeli de vardır. GPT-3 gibi büyük dil modellerinin eğitimi, aylar süren GPU hesaplamaları, tonlarca soğutma enerjisi ve yüz binlerce kilovat saat elektrik tüketimi gerektirir. Yapılan hesaplamalara göre, yalnızca GPT-3’ün eğitimi, yaklaşık 500 ton karbondioksit eşdeğeri salıma yol açtığı tahmin edilmektedir. Bu değer, bireysel ölçekte onlarca yıl boyunca karbon salımı yapmadan yaşayan bir insanın toplam emisyonuna yakındır. Yapay zekânın geleceği ne kadar umut verici olursa olsun, çevresel sürdürülebilirlik boyutuyla birlikte düşünülmesi gereken ciddi bir altyapı maliyeti bulunmaktadır.

Büyük yapay zekâ sistemlerinin eğitim ve işletme süreçleri ciddi enerji tüketimine neden olmaktadır. Green AI, bu durumu dengelemek için daha küçük, verimli ve çevre dostu modellerin geliştirilmesini teşvik eder. Yapay zekânın geleceği, yalnızca zekâ üretme değil, aynı zamanda sürdürülebilirliği sağlama kapasitesiyle değerlendirilecektir.